
Table of Contents
Overview
This post provides you code snippets so you can start working with AWS S3/Digital Ocean Spaces via java SDK quickly.
You can use AWS S3 SDK to access DigitalOcean Spaces.
Create key pair to feed to the client
Before working on the code, you need to create a key pair so you can access the buckets via SDK.
On Digital Ocean, you can log in to your dashboard and generate a key pair like so:
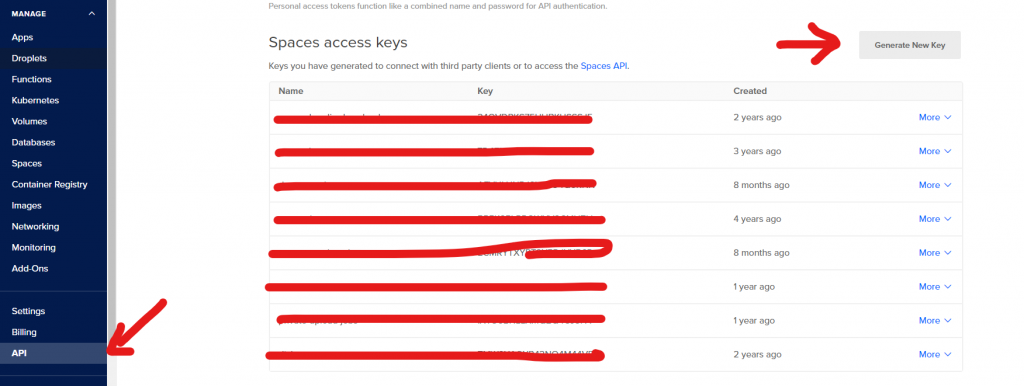
For AWS, the process is quite different. You need to create an IAM account with programming access then assign s3 access (Read/Write) depending on your needs.
For Digital Ocean, if you own a key pair, you have full CRUD access to the space (which is dangerous). AWS S3 is way better at managing access (and speed too).
If you have the key pair, let’s get started.
Create a client with authentication data
The first step is to create a client.
public GetClientWithAuthen(String bucketName, Region region)
{
AWSCredentialsProvider credentials =
new AWSStaticCredentialsProvider(new BasicAWSCredentials(KEY, SECRETS));
this.bucketName = bucketName;
return AmazonS3ClientBuilder.standard()
.withCredentials(credentials)
.withRegion(region)
.build();
}
This is all you need to build a client. Now you can use this to do various tasks on S3 (depending on the rights you give to this account, for AWS S3 of course, Digital Ocean keys have full Read/Write access).
Upload Object Private in S3
In S3 terminology, an Object is a file.
To upload a file/object, you can use this code:
public PutObjectResult uploadObjectPrivate(File file, String fileObjKeyName, String mimeType)
{
PutObjectRequest request = new PutObjectRequest(bucketName, fileObjKeyName, file)
.withCannedAcl(CannedAccessControlList.Private);
ObjectMetadata metadata = new ObjectMetadata();
metadata.setContentType(mimeType);
request.setMetadata(metadata);
PutObjectResult result = s3Client.putObject(request);
return result;
}
How do you know the upload is successful? The PutObjectResult object has a method named getContentMd5. If the result of that method is null, you know the upload has failed.
Upload objects and enable public read
In cases you want to enable public access (Read/Write), you can use the following code:
public PutObjectResult uploadObjectPrivate(File file, String fileObjKeyName, String mimeType)
{
PutObjectRequest request = new PutObjectRequest(bucketName, fileObjKeyName, file)
.withCannedAcl(CannedAccessControlList.PublicRead);
ObjectMetadata metadata = new ObjectMetadata();
metadata.setContentType(mimeType);
request.setMetadata(metadata);
PutObjectResult result = s3Client.putObject(request);
return result;
}
Enabling public writing is rare, however, in case you need that, just replace PublicRead with PublicReadWrite.
Download objects and write them to local files
There are quite many approaches when it comes to downloading files from S3 and storing them locally. The SDK has a method to do that actually. However, you may encounter file lock exceptions like so:
Caused by: com.amazonaws.services.s3.transfer.exception.FileLockException: Fail to lock /path/to/file for appendData=false at com.amazonaws.services.s3.internal.ServiceUtils.downloadToFile(ServiceUtils.java:292) at com.amazonaws.services.s3.internal.ServiceUtils.downloadObjectToFile(ServiceUtils.java:272) at com.amazonaws.services.s3.internal.ServiceUtils.retryableDownloadS3ObjectToFile(ServiceUtils.java:404) at com.amazonaws.services.s3.AmazonS3Client.getObject(AmazonS3Client.java:1438)
Thus, if you download many files and run the download tasks concurrently, it’s better (IMO) to follow these two steps:
- Generate a publicly accessible URL (remember to give that URL a short expiration time)
- Download the file and store on a local HDD using the old java way
Generate a publicly accessible URL
It’s quite simple to generate a public access URL using S3 SDK.
public URL generatePublicURL(String bucketName, String objectKey) {
try {
return myS3Client.generatePresignedUrl(bucketName, objectKey, null);
} catch (Exception ex) {
return null;
}
}
As you can see, I called the generatePresignedUrl with a null date. That means the link is never expired. Don’t be lazy and create a Date instance and pass it to that method. I’m just too old.
Download presigned URL and store it locally
Now you can download the URL using this code:
var saveToFile = new File("/path/to/local/file");
if (saveToFile.exists() && saveToFile.isDirectory())
return false;
if (!saveToFile.getParentFile().exists()) {
saveToFile.getParentFile().mkdirs();
}
//downloadUrl is the presigned URL above
try (BufferedInputStream in = new BufferedInputStream(downloadURL.openStream());
FileOutputStream fileOutputStream = new FileOutputStream(saveToFile)) {
byte dataBuffer[] = new byte[1024];
int bytesRead;
while ((bytesRead = in.read(dataBuffer, 0, 1024)) != -1) {
fileOutputStream.write(dataBuffer, 0, bytesRead);
}
} catch (IOException e) {
// handle exception
e.printStackTrace();
}List all objects in a bucket
There are times you want to list all objects in a bucket. For example, yesterday I need to download all from Digital Ocean and upload it to S3 (that’s why I’m writing this).
The naive question is: how can I get the list of all files? Mind you, I have nearly 2 million objects. That’s not possible.
The S3 SDK has a convenient method that let you list objects with a marker. You just need to move the marker until the end of your object list.
Think about database paging. It’s kind of similar.
This method list objects in a bucket:
public ObjectListing listObject(String bucketName, String prefix, String marker) {
var listingRequest = new ListObjectsRequest(bucketName, prefix,marker, null, 1000);
return myS3Client.listObjects(listingRequest);
}If you have many files, this one will not list all of your objects. You need a loop for that.
The best way to get all objects in your bucket is to loop through the method above with a marker. Each time you get a list of objects, store it somewhere (in a database for example).
Here is the code snippet:
String marker = null;
String prefix = null; //set a prefix if you prefer
while (true) {
var listing = doj.listObject(bucketName, prefix, marker);
var listRemotePaths = listing.getObjectSummaries().stream().map(t -> t.getKey()).collect(Collectors.toList());
//Store the listRemotePath somewhere here
if (!listing.isTruncated())
break;
marker = listing.getNextMarker();
}As you can see, I used a method called isTruncated. If this method returns true, that means there are more objects. If it returns false, that means you’ve reached the end of the list.
Delete an object using the S3 SDK
It’s quite simple to delete an object using S3 SDK:
public boolean deleteObject(String bucketName, String objectKey) {
try {
myS3Client.deleteObject(bucketName, objectKey);
return true;
} catch (AmazonServiceException e) {
return false;
}
}Conclusion
In this post, I’ve shown you how to do CRUD operations with AWS s3 and Digital Ocean spaces. They are similar in many cases. However, AWS s3 has finer access control. I used Digital Ocean spaces for years because it’s cheap. However, with my new applciations’ requirements (S3 is faster than Digital Ocean), I need to move most of my files to S3.

I build softwares that solve problems. I also love writing/documenting things I learn/want to learn.