
Table of Contents
Overview
One of the biggest questions I have when studying the functional interfaces in java.util.function is why the creators made DoubleConsumer (LongConsumer, IntConsumer) while there is already a Consumer interface that can handle any kind of object.
It turned out, they have solid reason to do so.
Boxing, unboxing, autoboxing primer
As you may already know, the Java primitive types (8 of them) have their wrapper counterpart (int has Integer, double has Double…). Converting from a primitive type to the wrapper type is called boxing and the opposite direction is called unboxing. Autoboxing is the process by which the Java compiler automatically converts a primitive type to its wrapper type.
Let’s consider the following example:
private static Boolean isEven(Integer number) {
if (number > 100)
return false;
return true;
}This method declares a return type of Boolean (object) while in its body, the return values are primitive. Java compiler does the conversion for you. That is called autoboxing.
Why use DoubleConsumer instead of Consumer<Double>?
It turned out, that autoboxing is not free. There is a performance overhead turning a primitive value into its equivalent wrapper type.
Let’s consider the following code to see the performance differences in number:
public static long runDoubleConsumerBenchmark(int iterations) {
DoubleConsumer doubleConsumer = (d) -> {
};
long startTime = System.nanoTime();
for (int i = 0; i < iterations; i++) {
doubleConsumer.accept(i);
}
long endTime = System.nanoTime();
return endTime - startTime;
}
public static long runConsumerBenchmark(int iterations) {
Consumer<Double> consumer = (d) -> {
};
long startTime = System.nanoTime();
for (int i = 0; i < iterations; i++) {
consumer.accept((double) i);
}
long endTime = System.nanoTime();
return endTime - startTime;
}What these two methods do is quite straightforward. Each method would loop through the iteration and call the accept function of the consumer. In order to strictly observe the effect of autoboxing, the accept methods in both consumers do nothing.
Let’s start with 100,000 iterations:
public static void main(String[] args) {
int[] iterationCounts = {100_000};
System.out.println("+------------+-----------------------+-------------------------+");
System.out.println("| Iterations | Using DoubleConsumer | Using Consumer<Double> |");
System.out.println("+------------+-----------------------+-------------------------+");
var nb = NumberFormat.getInstance();
for (int iterations : iterationCounts) {
long doubleConsumerTime = runDoubleConsumerBenchmark(iterations);
long consumerTime = runConsumerBenchmark(iterations);
System.out.printf("| %-10s | %-21s | %-23s |\n",
nb.format(iterations),
nb.format(doubleConsumerTime),
nb.format(consumerTime));
}
System.out.println("+------------+-----------------------+-------------------------+");
}
As you can see, the difference is quite significant. Using DoubleConsumer is notably faster than using Consumer<Double>.
Now let’s try 100,000,000 iterations:
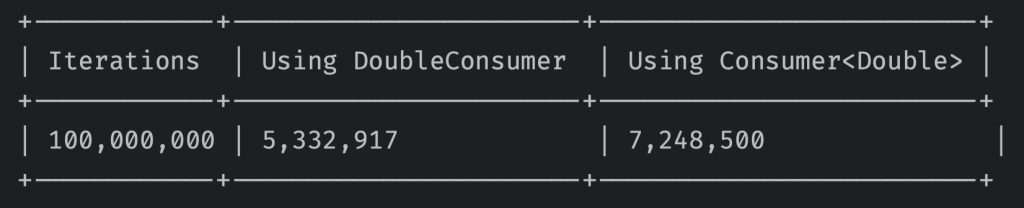
As you can see, using DoubleConsumer is still faster than using Consumer<Double> noticeably.
The reason why with 100 million iterations the code run isn’t significantly longer than 100k iterations I would like to discuss in a different post. My initial guess is because the JIT compiler was doing it job to optimize the code on the fly.
Conclusion
Now the reason why DoubleConsumer (and other Consumer/Predicate/Function… exists) is quite clear. For starters, it is to avoid the performance overhead of the boxing/unboxing process. Do you know there are additional reasons? Please let me know in the comment!

I build softwares that solve problems. I also love writing/documenting things I learn/want to learn.