MongoDB Index Tutorial

MongoDB Index fundamentals
If you have ever worked with any database (SQL or NoSQL), you probably know that the purpose of creating indexes is to speed up the queries at the cost of create/update/delete operations.
MongoDB is no exception.
MongoDB uses B-Tree as indexes’ data structure. This data structure offers fast queries. However, since the data is ordered, the update/create/delete operations are slower because, in addition to the operations themselves, the database still needs to create/update/delete records for the documents in the index tree.
Sample Data
This post uses data from the mflix collection from MongoDB. You can download the collections in the JSON format here:
https://github.com/datmt/mongodb-sample-dataset/tree/main/sample_mflix
Then import using the mongoimport command:
mongoimport --db flix --collection theaters --file theaters.jsonAs you may already know, you don’t need to create any database or collection beforehand.
After importing all the files, when running show dbs you’ll see the flix database is available:
Viewing imported data
Basic MongoDB Index Operations
Create an index
Creating an index in MongoDB is quite simple. You need to specify the fields you want to include in the index. You can specify one or multiple fields. For example, the following command creates an index on the name field of the users collection:
db.users.createIndex({name: 1})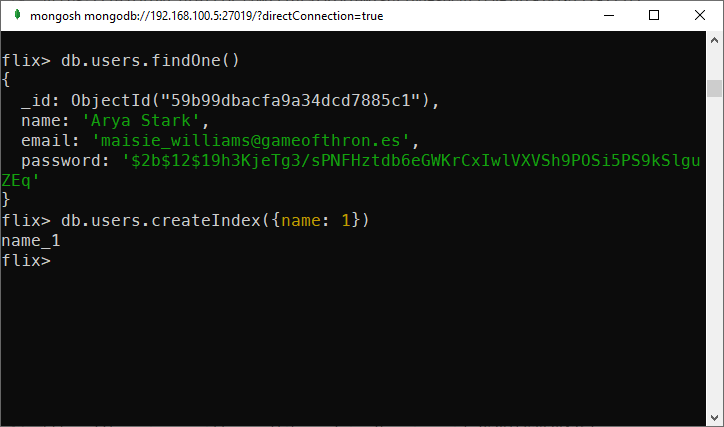
Create a new index in MongoDB
Getting all current indexes of a collection
To get all indexes of a collection, simply run the getIndexes method on the collection. Here is one example
db.users.getIndexes()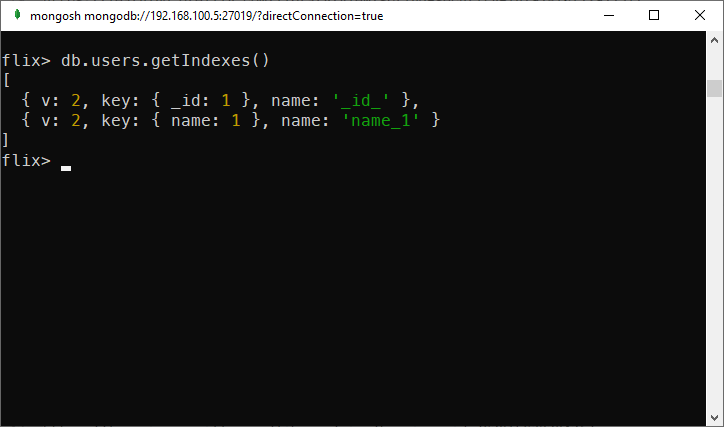
Getting all indexes of a collection
Drop an index
To drop an index from a collection, simply call dropIndex and pass in the index’s name:
db.users.dropIndex("name_1")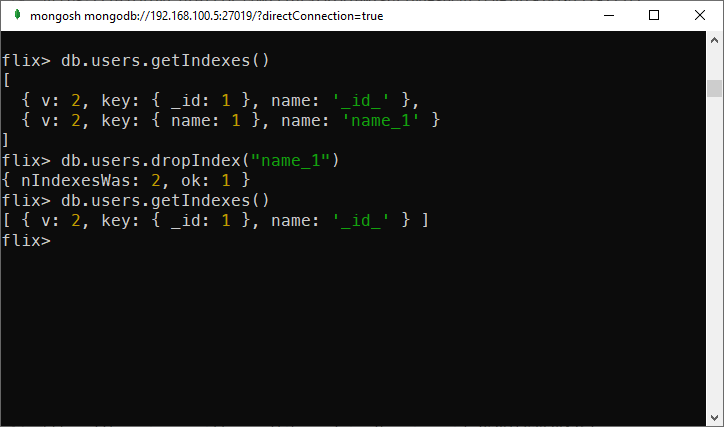
Drop an index in MongoDB
Types of MongoDB Index
Unique Index
Unique indexes are usually used to prevent duplication rather than improve performance. To create a unique index, simply pass {unique: true} in createIndex function.
For example, the command below creates a unique index on the name field of the users collection:
db.users.createIndex({name: 1}, {unique: true})Now, if I insert a new document that has name already exists in the collection, the MongoDB server will throw an error:
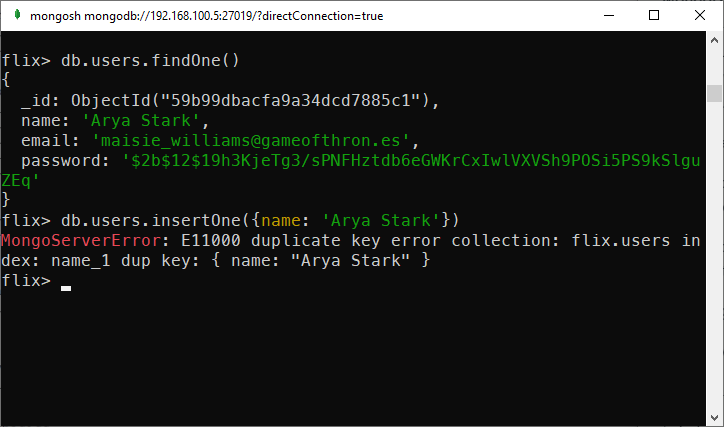
MongoDB throws an error on duplicate key insertion
Compound Index
A compound index is an index that consists of more than one field. Creating a compound index is a good idea when you query based on multiple fields.
Consider the movies collection with a sample document as below:
{
_id: ObjectId("573a1390f29313caabcd42e8"),
plot: 'A group of bandits stage a brazen train hold-up, only to find a determined posse hot on their heels.',
genres: [ 'Short', 'Western' ],
runtime: 11,
cast: [
'A.C. Abadie',
"Gilbert M. 'Broncho Billy' Anderson",
'George Barnes',
'Justus D. Barnes'
],
poster: 'https://m.media-amazon.com/images/M/MV5BMTU3NjE5NzYtYTYyNS00MDVmLWIwYjgtMmYwYWIxZDYyNzU2XkEyXkFqcGdeQXVyNzQzNzQxNzI@._V1_SY1000_SX677_AL_.jpg',
title: 'The Great Train Robbery',
fullplot: "Among the earliest existing films in American cinema - notable as the first film that presented a narrative story to tell - it depicts a group of cowboy outlaws who hold up a train and rob the passengers. They are then pursued by a Sheriff's posse. Several scenes have color included - all hand tinted.",
languages: [ 'English' ],
released: ISODate("1903-12-01T00:00:00.000Z"),
directors: [ 'Edwin S. Porter' ],
rated: 'TV-G',
awards: { wins: 1, nominations: 0, text: '1 win.' },
lastupdated: '2015-08-13 00:27:59.177000000',
year: 1903,
imdb: { rating: 7.4, votes: 9847, id: 439 },
countries: [ 'USA' ],
type: 'movie',
tomatoes: {
viewer: { rating: 3.7, numReviews: 2559, meter: 75 },
fresh: 6,
critic: { rating: 7.6, numReviews: 6, meter: 100 },
rotten: 0,
lastUpdated: ISODate("2015-08-08T19:16:10.000Z")
}
}From this document, you can create a compound index using two fields: countries and imdb.rating:
db.movies.createIndex({"countries": 1, "imdb.rating": 1})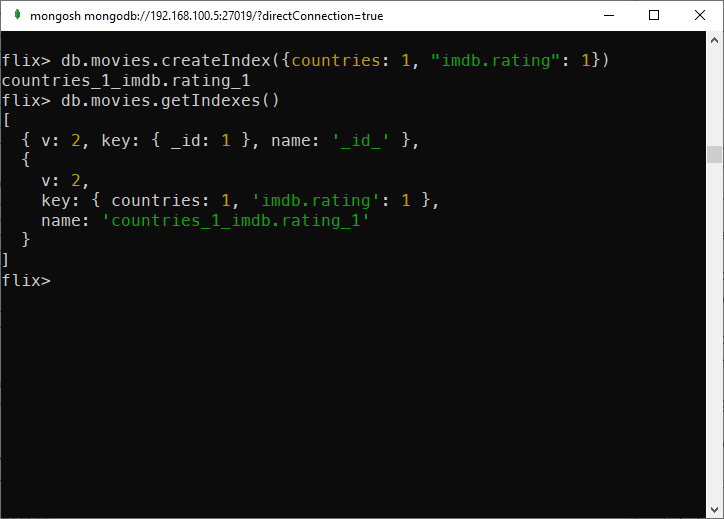
Create a compound index in MongoDB
Notice that compound indexes can be used even when the queries don’t include all fields of the indexes.
In the example above, when this query is run:
db.movies.find({"countries": "USA"})The compound index is also used.
I can verify this by adding explain before find
db.movies.explain().find({"countries": "USA"})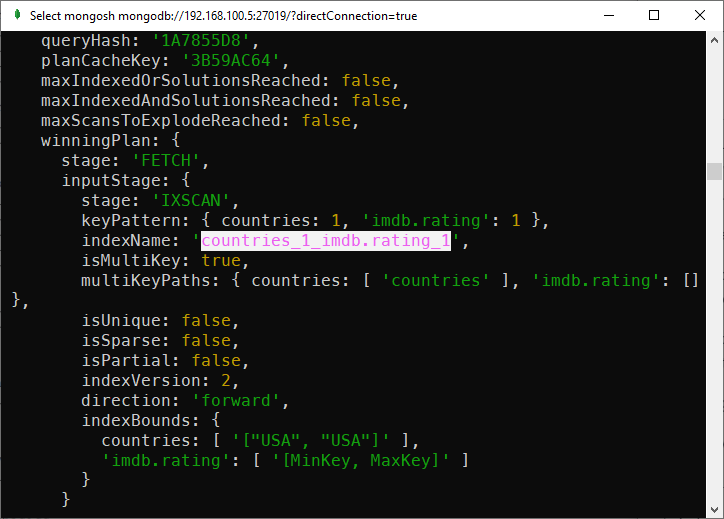
However, when you run the query for imdb.rating, the index is not used:
db.movies.explain().find({"imdb.rating": {$gt: 5}})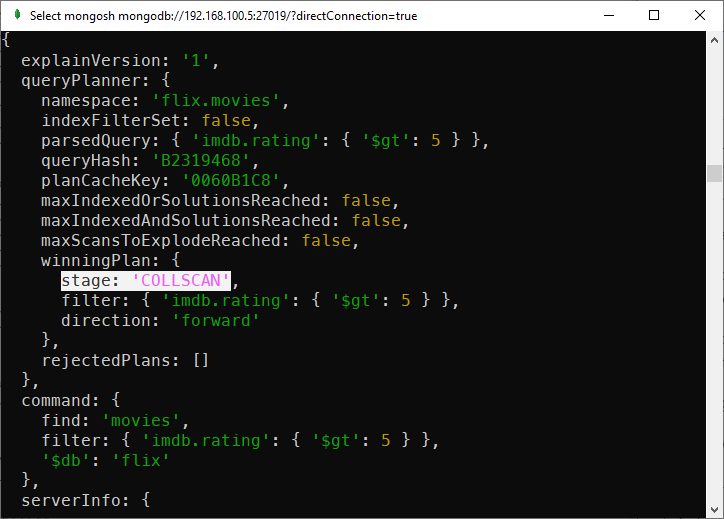
Compound index is not used
The index was not used, instead, MongoDB used column scan strategy.
This is because imdb.rating is not a leading attribute in the index. Leading attributes are the ones that appear first when creating the index.
If instead, you create this index:
db.movies.createIndex({"imdb.rating": 1, "countries": 1})When running the following query:
db.movies.explain().find({"imdb.rating": {$gt: 5}})You’ll see the index is used:
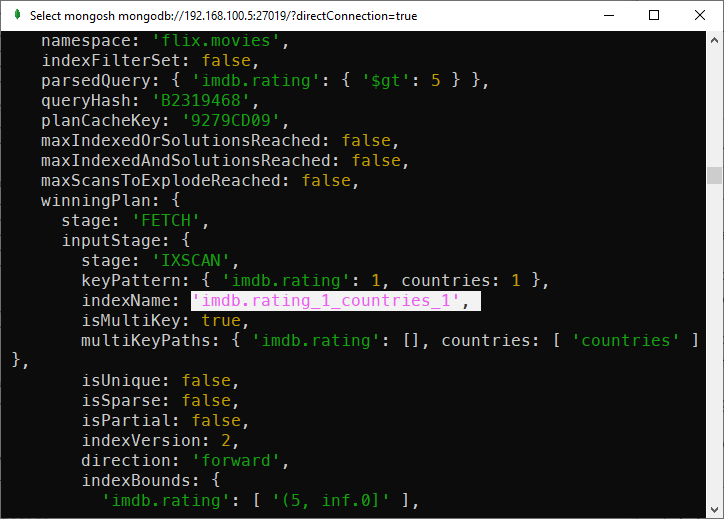
Importance of order of fields when creating an index
In addition, if you make a query with countries, imdb.rating and other fields (year for example) in this exact order:
db.movies.explain().find({"countries": "USA", "imdb.rating": {$gt: 5}, "year": {$gt: 1990}})Then then index created with countries specified first then imdb.rating is used:
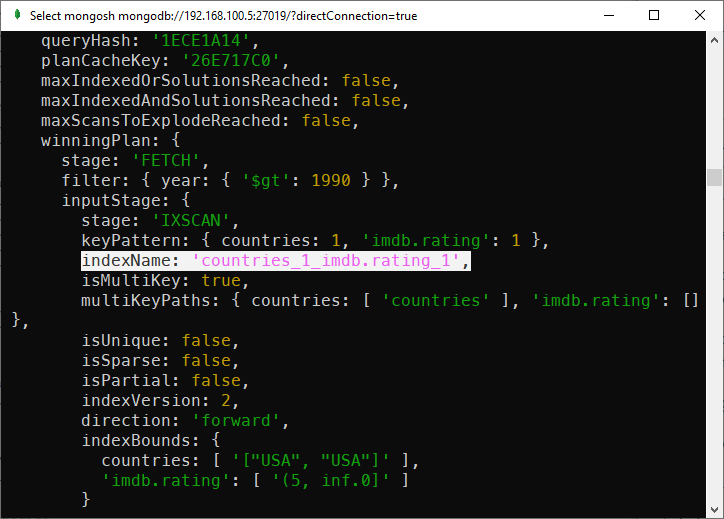
A compound index is used in a non-exact match query
MongoDB text Index
MongoDB supports full-text search. You can create a text index to search in text fields.
In the mflix database, the comments collection stores the comments of users on movies. The text field of these documents is ideal for full text search.
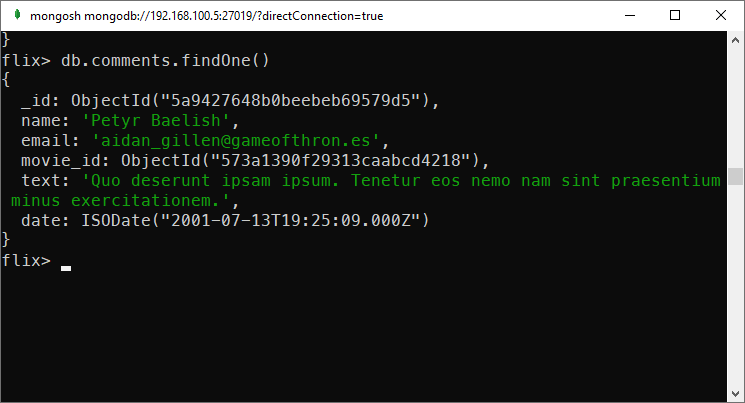
Structure of a comment document in mflix database
As you can see, without a text index, if you want to find comments that contain the word “deserunt”, you would need to run a regex query:
db.comments.find({ text: {$regex: /.*deserunt.*/i }})If you run explain, you’ll see MongoDB use COLSCAN through all documents in the collection:
db.comments.explain("executionStats").find({ text: {$regex: /.*deserunt.*/i }})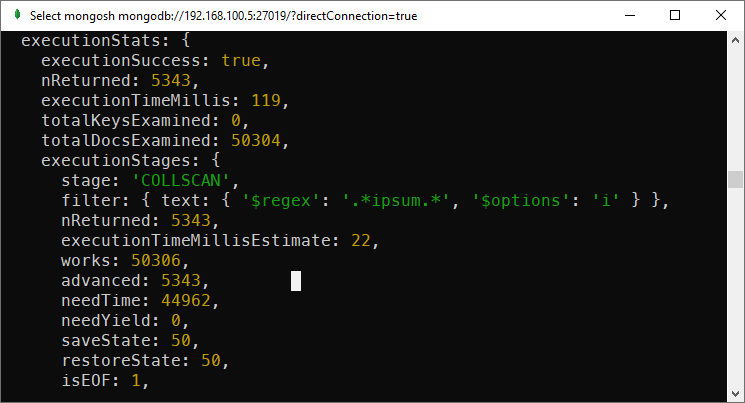
Regex search scan all documents in the collection
Let’s create a text index and see if you can improve the query by having this index:
db.comments.createIndex({"text": "text"})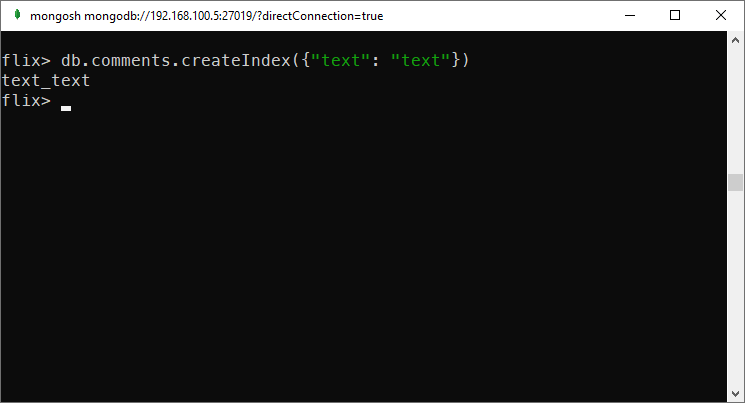
Remember that you can have only one text index per collection so after creating one if you create another text index, you will get an error.
Now let’s see if using MongoDB text index would make any difference:
db.comments.explain("executionStats").find({ $text: { $search: "deserunt" } })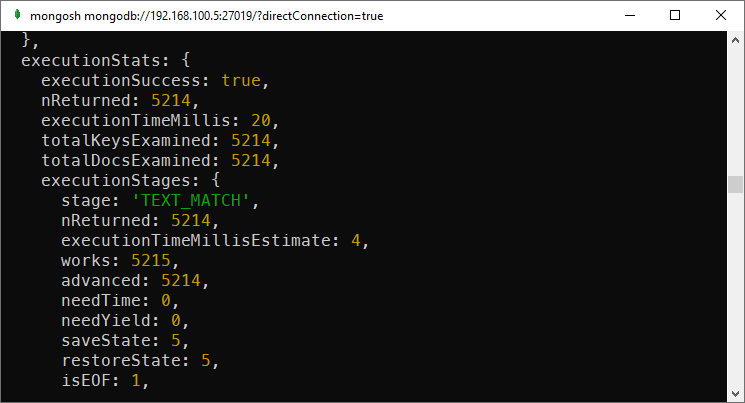
Search for text using text index in MongoDB
As you can see, instead of scanning through over 50k documents, when having the index, there were only over 5k documents examined.
The execution time is significantly lower (20 compared to 119).
MongoDB Partial Index
A partial index, as the name suggests, covers only a subset of documents in a collection.
In the movies collection, let’s say we want to create an index for movies that have ratings greater than 6. Creating a partial index based on that condition is quite simple like this:
db.movies.createIndex(
{ "imdb.rating": 1 },
{ partialFilterExpression: { "imdb.rating": { $gt: 6 } } }
)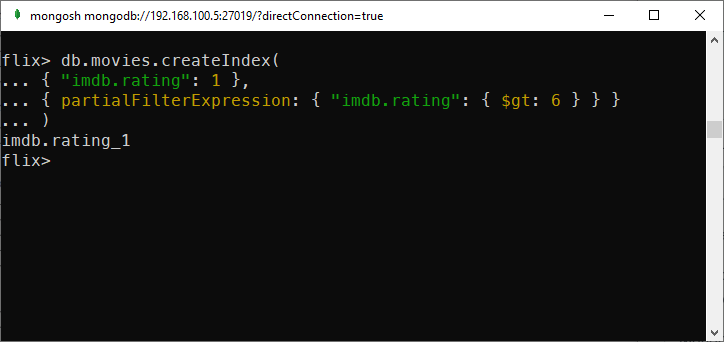
Creating a partial index
By having this index (and assuming there is no other indexes), this query would use the index:
db.movies.find({ "imdb.rating" : 7 })But this one wouldn’t:
db.movies.find({ "imdb.rating" : 5 })MongoDB Sparse Index
A sparse index only index documents that contain at least one of the indexed attributes.
Given this collection with three documents:
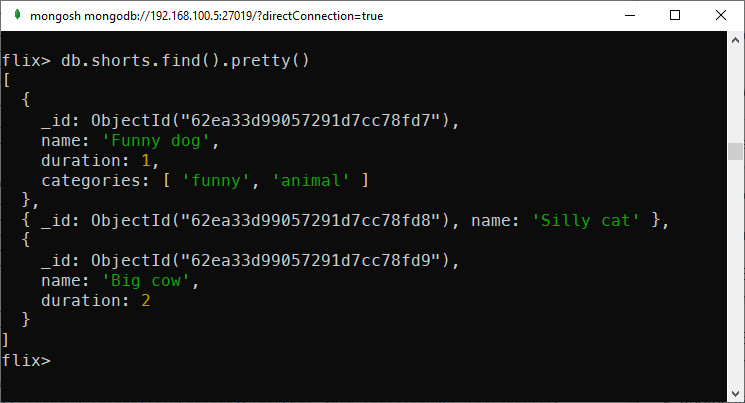
A simple collection
As you can see, the first document has three fields: name, duration, and categories. The second document only has the name field and the last one misses the category field.
If I create a sparse index on duration and categories, only the last one is not indexed.
You can create a sparse index using this command:
db.shorts.createIndex({duration: 1, categories: 1}, {sparse: true})The advantage of a sparse index is that it has a smaller size (because it doesn’t index all documents in the collection). The downside of using this index is that when you run find on the indexed attribute with $exists: true as a condition, the index is not used. Instead, MongoDB will use COLSCAN instead.
MongoDB Wildcard Index
When you create a wildcard index, you create indexes for all attributes in a child document.
Consider this collection has only one document:
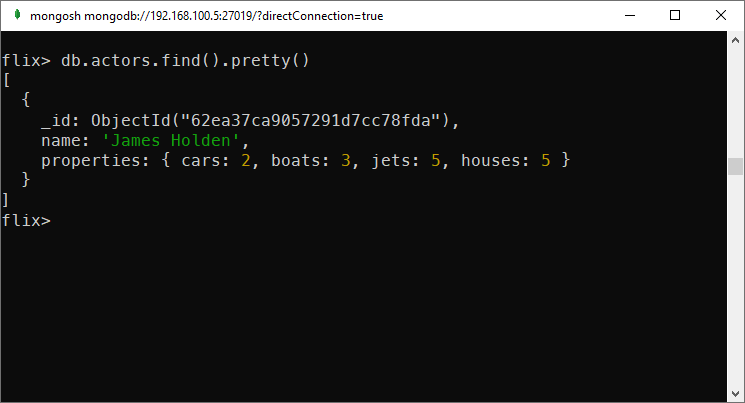
A collection with one document
This command will create a wildcard index for all the attributes of properties:
db.actors.createIndex({"properties.$**": 1})Conclusion
In this post, I’ve introduced the most common types of indexes in MongoDB, how to create them, and some important points you need to pay attention to when using the indexes.